-
[사례연구] 네이버 사례 대용량 XLSX 파일 다운로드 처리ApplicationArchitect 2022. 3. 23. 18:06
streaming API를 사용한 네이버페이의 대형 XLSX 파일 다운로드 구현
2021.04.09|25029
네이버페이에서는 엄청난 양의 데이터가 생성됩니다. 자신이 생성한 많은 데이터를 한꺼번에 보고 싶어 하는 판매자를 위해 네이버페이는 Microsoft Excel 통합 문서 파일(XLSX 파일) 다운로드 기능을 제공합니다.
일반적인 웹 페이지는 페이징(paging)을 사용합니다. 해당 데이터가 어떤 기간에 생성되었든 한 페이지에 표시할 수 있는 내용만 표시합니다.
하지만 XLSX 파일은 사용자가 원하는 기간 또는 원하는 상태에 해당하는 모든 데이터를 포함합니다. 따라서 데이터의 최대 크기를 알고 있는 페이징과 달리 데이터의 최대 크기를 알 수가 없습니다. 지금까지 네이버페이에서는 20만 row의 데이터 다운로드를 시도하는 일도 있었습니다. 이렇게 크기가 큰 XLSX 파일을 생성하려고 하면 OOM(out of memory)이 발생할 가능성도 있습니다.
이 글에서는 네이버페이가 어떻게 OOM을 회피하며 데이터를 XLSX 파일로 변환하는지 알아보겠습니다.
XLSX 파일은 어떤 파일일까
더 좋은 서비스를 더 좋은 성능으로 제공하기 위해서는 항상 기본부터 살펴봐야 한다. XLSX 파일이 어떤 파일인지 살펴봐야 더 빠르고 안정적인 XLSX 파일 생성 서비스를 만들 수 있다.
표준이 있는 파일
XLSX 파일의 형식은 OOXML(Open Office XML)이다. PPTX, DOCX 파일도 OOXML 형식을 사용한다. OOXML은 이름처럼 XML을 기반으로 데이터를 저장하고 표현한다. 그렇다면 왜 XLSX 파일을 텍스트 편집기로 열면 XML 형식의 텍스트가 보이지 않을까? 이는 XLSX 파일이 여러 XML 파일을 포함하는 폴더를 압축한 파일이기 때문이다. 실제로 XLSX 파일의 확장자를 .zip으로 변경한 뒤 압축을 해제하면 다음과 같은 구조를 볼 수 있다.
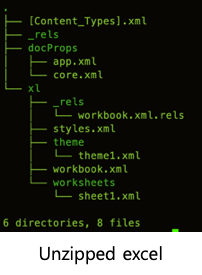
row 정보는 모두 {sheetName}.xml 파일에 저장된다. 이 파일에는 필요한 정보 외에 XML 오버헤드도 굉장히 많기 때문에 row 몇만 개의 정보를 모두 메모리에 올리면 위험한 상태가 된다. 서버가 이 XLSX 파일만 생성하는 것이 아니라면 더욱 그렇다. 따라서 {sheetName}.xml 파일은 stream 처리가 되어야 한다.
서식 정보는 style.xml 파일에 저장된다. 복잡하고 화려한 서식을 사용하는 경우가 아니라면 style.xml 파일은 따로 신경쓰지 않아도 된다.
shared string이라는 기능도 있는데, 이는 sheet.xml 파일에 string 전체를 쓰는 대신 1, 2, 3과 같은 숫자를 쓰고 읽을 때 sharedString.xml 파일에서 읽어오는 기능이다.

이 기능을 사용하면 전체 XLSX 파일의 크기를 줄일 수 있지만 XLSX 파일을 생성할 때 shared string의 전체 값을 메모리에 올려둬야 하기 때문에 생성하는 XLSX 파일 크기가 큰 경우에는 위험 부담이 있다. 또한 XLSX 파일은 압축 파일이기 때문에 용량을 줄이기 위해선 shared string을 사용해 겹치는 string을 줄이는 것보다는 압축 레벨을 올리는 것이 더욱 효과적이었다.
기존의 XLSX 파일 생성 구조
기존의 XLSX 파일 생성 구조는 다음과 같았다.

MyBatis의 resultHandler에서 row 한 개씩 XLSX 파일에 작성하고 XLSX 파일 생성이 완료되면 네이버의 세션 관리, 메시지 전달 사내 플랫폼인 Session.io에 이를 알려준다. 그러면 Session.io는 사용자의 브라우저에 푸시하여 XLSX 파일을 다운로드하게 한다. 이 방법으로 한 요청이 Tomcat 스레드를 오래 차지하지 않게 했다. 또한 서버가 XLSX 파일을 생성하는 동안 사용자가 "왜 반응이 없지?"라며 한 번 더 클릭하는 일을 방지하기 위해, 네이버에서 오픈소스화한 메모리 캐쉬 클라우드 Arcus에 XLSX 파일을 생성하고 있다는 정보를 담는다.
이번 XLSX 파일 다운로드를 개편하면서 어떤 구조가 좋을지 2가지의 선택지 중 고민이 있었다.
첫 번째는 기존 구조를 그대로 사용하는 것이었다(소스는 API 서버에 있되 인스턴스를 분리). 이 구조의 단점은 중간 진행 단계를 사용자가 모른다는 점이다. 사용자는 XLSX 파일 생성이 완료되어야지만 다운로드 링크를 받고 다운로드할 수 있다. 또한 API 서버 코드에 현재 없는 사용자와 직접 맞닿는 API가 들어가야 한다는 불편함도 있었다. 또 XLSX 파일 생성에 Arcus나 Session.io와 같은 외부 의존성이 필요하다.
두 번째는 API 서버를 호출하여 XLSX 파일을 생성하는 서버를 만드는 것이다.

이 구조는 API 서버 코드에 직접적으로 XLSX 파일을 만드는 API가 들어가지 않아도 되기 때문에 API 서버 관리가 쉽다. API 서버에서 해당 API의 의존성도 제거할 수 있고 또한 구조 개편 전과 다르게 Tomcat 앞에 Node.js가 있기 때문에, Node.js에서 API 서버를 호출하여 XLSX 파일을 생성할 수 있다면 Node.js에서 생성하는 것이 다른 API들처럼 각종 인증 처리와 formatting 처리를 Node.js에서 할 수 있다는 장점이 있다.
JavaScript로 XLSX 파일 생성하기
Java에는 굉장히 유명한 라이브러리인 POI가 있기 때문에 Java에서 XLSX 파일을 생성한다고 하면 따로 조사할 필요가 없지만 JavaScript도 고려 중이었기 때문에 JavaScript에서 XLSX 파일을 생성하는 오픈 소스 라이브러리를 다음과 같은 방법으로 조사해 보았다.
- Github에서 Excel 검색
- Languages 옵션에서 JavaScript 클릭
- Most stars 순서로 정렬
- 하나씩 필요한 기능을 제공하는지 확인하고 테스트
위 그림과 같이 여러 개의 오픈 소스 라이브러리가 있는데 그 중 ExcelJS가 2019년 6월 기준 JavaScript에서 XLSX streaming을 제공하는 유일한 라이브러리였으며 그 밖에 필요한 다음과 같은 기능을 모두 제공했다.
- 서식 제공
- row 한 개씩 메모리에서 flush 가능(OOM 회피)
- 그다지 어렵지 않은 사용
따라서 ExcelJS를 사용해 보기로 하고 Java에서 사용하는 POI와 성능을 비교해 보았다. 다음은 XLSX 파일의 cell 개수에 따라 단위 시간(밀리초)당 쓴 cell의 개수이다(웜업으로 1,600개의 cell이 포함된 XLSX 파일을 100번 쓴 이후 측정).
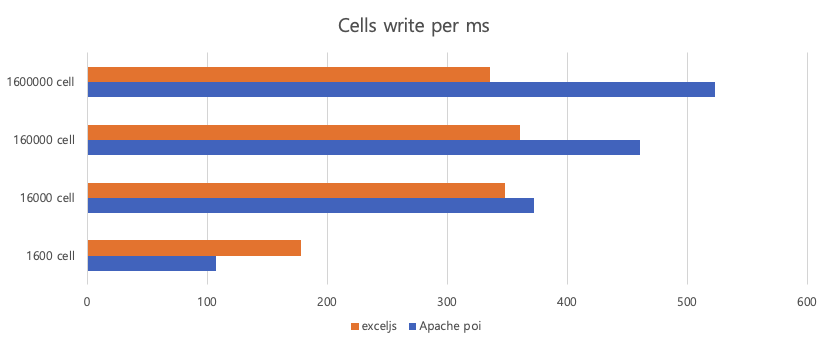
많은 데이터를 쓸수록 POI가 ExcelJS에 비해 빠르다. 즉 POI는 크기가 큰 XLSX 파일 생성 시 ExcelJS에 비해 성능상 이점이 있다. 하지만 단점이 하나 있는데 sheet.xml 파일을 임시 파일에 쓴다는 것이다. 이 때문에 response stream에 바로 XLSX 파일을 작성할 수 없다. 이 단점은 다음과 같은 차이로 나타난다.
위는 ExcelJS, 아래는 POI를 사용했을 때의 동작이다. ExcelJS는 다운로드 창이 바로 나타나는데 POI는 다운로드 창이 나타나기까지 시간이 걸리는 것을 볼 수 있다. 이는 사용자 경험상 큰 차이이다. POI를 사용한 경우에는 사용자 입장에서 버튼 클릭 후 몇 초간 아무 반응을 얻을 수 없다. 실제로 고객센터에 이 문제에 대한 문의가 지속적으로 오는 상태였다.
ExcelJS를 사용하면 버튼 클릭 즉시 다운로드 창이 나타나기 때문에 즉각적인 반응을 보여준다는 측면에서 더 나은 사용성을 제공한다. 따라서 크기가 큰 XLSX 파일을 생성하는 경우 성능이 조금 낮아지더라도 현재 구조에 적절한 방법과 더 좋은 사용자 경험을 위하여 ExcelJS를 선택했다.
이렇게 ExcelJS를 사용함에 따라 Node.js가 XLSX 파일을 생성했으면 좋겠다는 요구 사항과 XLSX 파일을 생성할 때 메모리를 너무 많이 사용하지 않았으면 좋겠다는 요구 사항을 만족할 수 있게 되었다. 또한 사용자의 response stream에 바로 XLSX 파일을 줄 수 있으므로 기존 XLSX 파일 생성에 사용하던 Arcus나 Session.io가 필요하지 않게 되었다.

Tomcat에서 Node.js로 데이터 주기
이제 XLSX 파일을 메모리 걱정 없이 생성할 수 있게 되었다. 그것도 Node.js에서. 이제 Tomcat과 Node.js 사이의 차례이다. 가장 먼저 고려했던 것은 페이징이다. 페이징을 사용한다면 이미 사용 중인 API가 있었기 때문에 추가로 개발을 하지 않아도 되었다. 또 굉장히 만들기 쉽다는 이점도 있었다.
하지만 네이버페이는 지금 XLSX 파일 생성에 페이징을 사용하지 않고 있다. 이유는 단 한 가지, 페이징이 너무 느리다는 것이다. 페이징에 필요한 ORDER BY 때문에 데이터베이스는 계속해서 전체 레코드를 정렬해야 했고 이는 느린 쿼리가 많은 XLSX 파일 생성에 적합하지 않았다. 따라서 다른 방법이 필요했다. 특히 I/O의 횟수를 줄여야 했다.
한 번의 I/O로 필요한 모든 row를 가져오는 것은 말은 쉽다. 그리고 실제로 쿼리 수정도 쉬웠다. 그저 페이징에 사용하던 LIMIT을 삭제하면 된다. 하지만 이렇게 하면 정말로 모든 row가 메모리에 들어온다. 이는 곧 메모리를 너무 많이 사용해서 위험할 수 있다는 뜻이기도 하다. 따라서 I/O는 한 번만 발생하면서 모든 row를 메모리에 올리지는 않을 수 있어야 했다. row를 한 개씩 데이터베이스에서 가져와 한 개씩 Node.js로 주는 방법이 필요했다.
Node.js로 row 한 개씩 streaming
다행히 spring-webflux가 해당 구조를 지원했다. 그것도 매우 간단했다. 그저 Controller에서 Flux만 반환하면 된다.
@GetMapping(path="/coupons-stream", produces=APPLICATION_NDJSON) public Flux<CouponDto> getCouponStream(CouponSearchParams params) { return couponSearchService.findFlux(params) .map(CouponDto::from); }위와 같이 Flux를 Controller에서 반환하면 NDJSON 형태로 데이터가 streaming된다. NDJSON은 다음과 같이 new line으로 row를 쪼개는 형식이다.
{"json":"object"}\n {"json":"object"}\n다음은 해당 API의 response 예시이다.
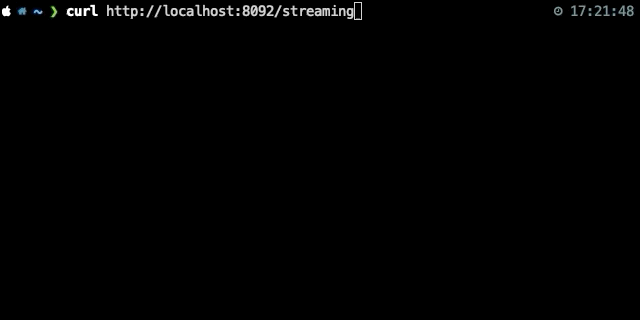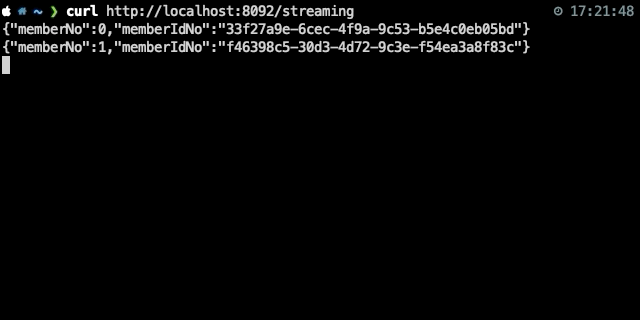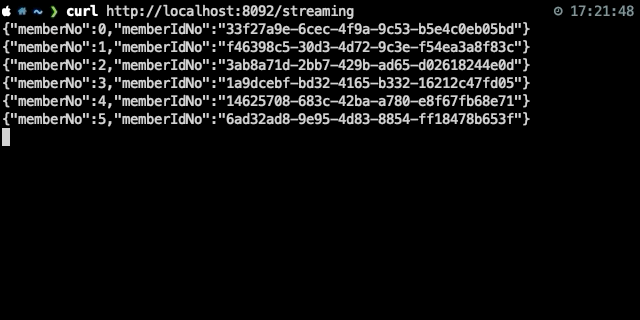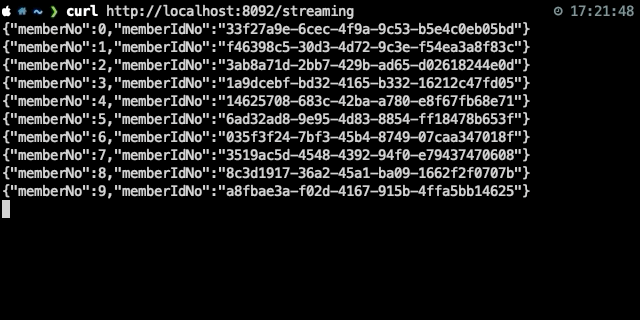
Node.js에서는 간단하게 다음과 같이 data 이벤트마다 XLSX 파일에 row를 flush하도록 하면 된다.
const jsonStream = JSONStream(); jsonStream.on('data', json => { excelUtil.writeRow(sheet, json, formatter) });데이터베이스에서 row를 한 개씩 가져오기
우리는 몇 개일지 모르는 쿼리 결과를 OOM을 회피하며 streaming하고 싶었다. 하지만 이 기능은 없었다. 이 기능을 만들어내기 위해 스레드를 하나 더 사용했다. 학교에서 배운 Producer & Consumer 모델을 사용해서 해당 기능을 제공했다.

Producer는 데이터베이스에서 row를 가져오고 Consumer는 Producer가 가져온 row를 가져간다. 이때 Consumer와 Producer는 BlockingQueue를 통해서 통신한다. 데이터베이스에 back pressure를 따로 줄 수 없기 때문에 blocking queue가 꽉 차 있는 경우 insert하는 스레드를 재우는 형식으로 back pressure 역할을 대신했다. 이를 통해 Consumer가 처리할 능력이 되지 않음에도 Producer가 메모리에 데이터를 무작정 넣는 일이 없도록 방지했다.
위 코드는 spring-jdbc-plus에 있다. 해당 코드를 사용하여 Flux를 generate했고 앞에서 설명한 spring-webflux를 사용하여 Node.js로 row를 한 개씩 streaming했다.
최종적으로는 다음과 같은 구조가 되었다.

이 구조를 사용하면서 네이버페이는 쿼리를 한 번만 함에도 불구하고 지금까지 단 한 번도 OOM이 발생하지 않았다.
적용하면서
XLSX 파일 다운로드 컴포넌트 안전하게 교체하기
이제 클라이언트에서 새로운 XLSX 파일 다운로드 기능으로 안전하게 교체하는 일만 남았다. XLSX 파일 다운로드는 네이버페이의 사업주 입장에서 가장 핵심적인 기능 중 하나이기 때문에, 새롭게 교체되는 코드가 오류 없이 동작해야 했고 만약 문제가 있다면 기존의 것으로 빠르게 롤백되어야 했다.
이 문제를 해결하기 위해 사내 서비스인 lambda를 활용했다. lambda는 별도의 서버 없이 특정 이벤트에 대응하여 코드를 실행하거나 직접 코드를 실행할 수 있는 serverless computing 또는 function as a service(FaaS) 플랫폼이다. 개발자가 미리 설정한 switch flag를 렌더링 Node.js 서버에서 호출하고 이를 react context로 주입해 flag에 의해 신/구 버튼의 렌더링을 제어했다. 혹시라도 문제가 발생한다면 재배포 없이 lambda 서비스에서 flag만 수정해서 기존의 버튼 컴포넌트로 렌더링시킬 수 있다. 비록 새로 고침을 해야 바뀐 컴포넌트를 렌더링시킬 수 있다는 단점이 있기는 하지만 최소 20분 이상 걸리는 배포 과정 없이 기능을 단 몇 초만에 자유롭게 바꿀 수 있다는 점에서 굉장히 안전하고 효율적인 방법이라고 생각한다.
POI를 ExcelJS로 교체하며 발생했던 이슈
네이버페이와 스마트스토어를 이용하는 사업주는 XLSX 파일을 사용해 배송업체에 상품을 등록하는 경우가 많다. 이때 특정 배송업체에서 ExcelJS로 생성한 파일이 읽히지 않는 이슈가 있었다. 배송업체가 XLSX 파일을 읽는 코드를 직접 확인하기 어려우므로, POI로 생성한 XLSX 파일과 ExcelJS로 생성한 XLSX 파일을 압축 해제하여 일일이 비교하는 약간 원시적인 방법으로 문제의 원인을 찾았다.
XLSX 파일을 구성하는 XML 파일에서 워크시트의 사용 범위를 지정하는 <dimension> 요소가 ExcelJS로 생성한 XLSX 파일에는 없어서 발생한 이슈였다. ExcelJS는 stream 방식의 특성상 최종 결과의 범위를 알 수 없으므로 따로 <dimension> 요소를 집어넣지 않는데, POI의 특정 버전이 이를 읽는 데 문제가 있었다(참고: https://github.com/exceljs/exceljs/blob/18fde32d1b7841210f3e396fb3ea4fd947c83320/lib/stream/xlsx/worksheet-writer.js).
// for some reason, Excel can't handle dimensions at the bottom of the file // this._writeDimensions();그래서 어쩔 수 없이 ExcelJS를 fork해서 코드를 다음과 같이 수정함으로써 이 문제를 해결했다.
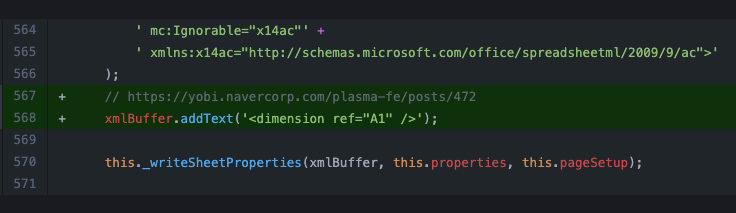
네이버페이와 스마트스토어 비지니스는 많은 곳에 얽혀 있기 때문에, 이처럼 회사의 서비스 외의 다른 곳에서 이슈가 발생하여 코드를 변경해야 하는 경우가 있었다.
마치며
성능을 개선하려면 병목을 잘 파악하자. 호박을 자를 때는 식칼이면 충분하다. 호박을 자르기 위해 광선검이나 청룡언월도를 찾는 사람은 주변에 없을 것이다.
네이버페이의 XLSX 파일 생성은 데이터베이스에서 데이터를 가져오는 부분이 병목이었다. 그런데 이 병목을 제대로 파악하지 않고 Tomcat과 Node.js 간 streaming 방법을 깊게 고민했었다. gRPC를 사용하려 했다가 사용성이 좋다는 이유로 성능이 비슷한 RSocket도 사용해 보았다. 하지만 결국 성능의 발목을 잡는 것은 데이터베이스에서 데이터를 가져오는 부분이었다.
spring-webflux를 사용하는 방법은 gRPC와 RSocket을 사용하는 방법에 비해 속도는 반 정도지만 결국 전체 성능은 비슷했다. 그래서 사용이 가장 쉬웠던 spring-webflux를 선택했다. 병목으로 인해 필요한 처리량은 호박에 불과한데 옆에 있는 식칼인 spring-webflux를 두고 gRPC(광선검)와 RSocket(청룡언월도)를 찾았던 셈이다. 성능을 개선하기 전에 병목을 잘 파악하면 큰 도움이 될 것이다.
필자들이 속한 조직에서는 네이버페이의 주문/혜택/정산 시스템 아키텍처를 개편하는 프로젝트를 진행하고 있다. 이 글에서 다룬 XLSX 파일 다운로드 아키텍처와 기술 스택의 변경도 그 프로젝트의 한 부분이다. 민감한 대량 상거래 데이터를 안정적으로 처리해야 하는 도전 거리가 넘쳐나는 프로젝트이다. 관심 있는 분들은 네이버 월간 영입 : 기술 직군에서 'Platform Labs' 의 '네이버페이 시스템 리뉴얼 프로젝트 서버 개발'로 지원하기 바란다.
'ApplicationArchitect' 카테고리의 다른 글
Circuit Breaker 패턴 (0) 2022.03.30 제한(Throttling) 패턴 (0) 2022.03.30 10 Design Patterns every Software Architect and Software Engineer must know (0) 2022.03.29 MSA - 서비스 디스커버리 패턴 (0) 2022.02.07 MSA - 아키텍처 설계 (0) 2022.02.07